We are now managing IT systems for some 170 schools in tens of cities around Finland. The schools have close to 8000 computers in total. The number of laptops is still relatively small, but approaching 1000. All of this is now managed with Puavo.
Puavo has been built over the years to serve our use case - lots of nearly identical centrally managed systems that still need separate user directories and storage areas. Every city has its own user directory and device inventory and every school has local teacher admins that do some of the tasks using Puavo. We do not run separate instances of everything for every city or school, but all the management tools are hosted in one place. Only the functions that need to be within school LAN are there.
There’s more about Puavo’s organisation model in an earlier post.
Puavo started as a user management and a simple inventory tool to help us serve teachers and pupils better. The first versions could only handle netbooting LTSP thin and fat clients and lot of management was done with other tools. Now Puavo is a set of tools that both store data and provide APIs that can be used by tools that integrate to the desktop.
Our current model is to use a single read-only desktop image file that can be used on all different devices - netbooting thin and fat clients, terminal servers and laptops. The image supports a huge variety of hardware, thanks to Ubuntu and linux in general. The image file is always stored as a file and it is not unpacked on laptops either. The image is a read-only image which means that users cannot install anything on the devices themselves. Adding new applications requires more testing, but this testing then benefits all of our users at once. Home directories are available normally for users to store their data. Web based services are also taking away the need for locally installed applications.
Puavo itself does not mandate image based installations and it can be used to manage also normal desktop installations.
How we got here? History of desktop management at Opinsys
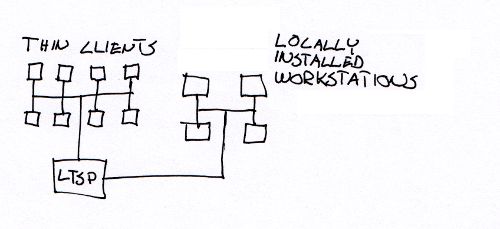
Step 1 - LTSP thin clients
We have been running our systems using LTSP thin and fat clients for quite a few years. When we started almost 10 years ago it was all thin clients. At first we were running only really old hardware. Nowadays I wonder how those machines with 64MB could actually be used as thin clients. There was no fat client support in LTSP, so we deployed some locally installed Ubuntu workstations on the side. We really didn’t have tools to manage anything in large scale. Some LDAP directories were installed locally and lts.conf files were modified when needed. This was enough to handle a few hundred thin clients and a few dozen workstations.
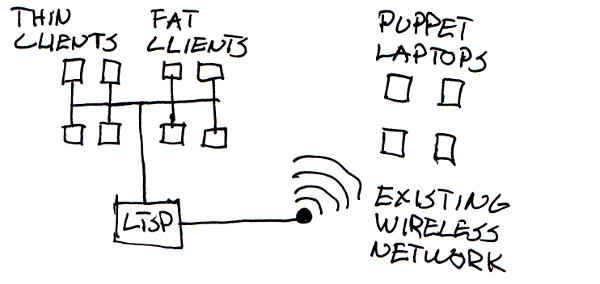
Step 2 - LTSP fat clients and laptops with Puppet
After some years we started deploying fat clients that replaced the locally installed workstations. The number of fat clients grew slowly and we built our first management tools to manage everything. Around this time we started experimenting with laptop management tools for the first time. LTSP makes everything super simple as there’s just one image and server to update, but with laptops that was not possible. We learnt about Puppet that automates a lot of administration tasks and wrote our desktop rules with it. LTSP servers, fat client image and laptops all used the same desktop configuration. Puppet handled server and laptop package and configuration updates.
Puppet worked quite well, but over time the configurations changed quite a bit and as new packages were installed, some old ones were removed. As we kept installing new laptops and servers in small batches, there were minor differences between old and new installations. We had all kinds of hardware - super fast new laptops, old laptops, new underpowered netbooks. On some of the machines running Puppet was way too heavy and users often shut down the machines when updates were running. This led to occasional boot failures as kernel packages were corrupted. Supporting these was not really our dream come true. Sometimes the laptops were not used for a month and when they were all started at once, Puppet would crash the school’s wireless network when downloading the updates.
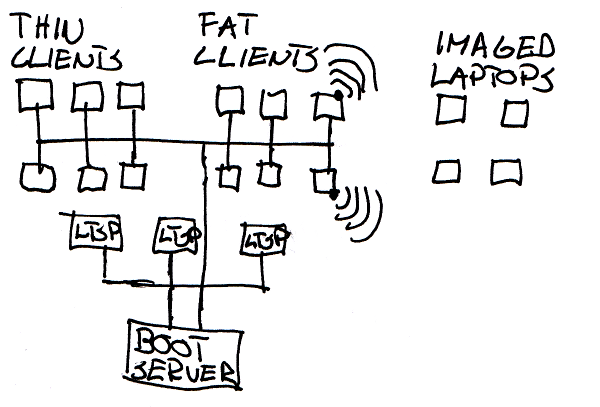
Step 3 - Netboot devices as wireless access points
Many wireless networks in schools are built to minimize the number of access points. When the access point is behind two walls and 25 laptops are used at once, nothing works. We thought hard about the problem and came up with an idea of turning the teacher workstations into access points. As every classroom already has a workstation for the teacher and there’s a wired connection to it, why not just share the connection? So we installed wlan dongles in the workstations and installed access point software on the workstations. The wireless traffic is tunneled to the server that can then manage it separately from the rest of the traffic. Puavo is used to manage the wireless network configuration.
Step 4 - One image for all devices
Over time we got over the problems and laptops became stable. But there was a problem - all the wired workstations booted from the network and used a single image that we could test easily, but laptops would require additional work for testing as we needed to test a lot of migration scenarios. We thought that maybe it would be possible to run the same netboot image on laptops and it indeed was. We had to do some changes to the normal LTSP code, but now we have tools in place to support all this. We release now a single weekly image that runs all our desktops. When laptop is installed, it is booted once using PXE and registered in Puavo’s hardward inventory like any other device. It then copies the image over the network in a few minutes and installs GRUB. GRUB knows how to load kernel and initrd from the image, so there’s just the single squashfs image file on the harddrive. Changing the image changes the operating system at once. Installing a laptop doesn’t take more than 5 minutes, so opening the retail packaging takes already more time than the software installation.
Updating laptops is still a bit different from netboot devices, but now it is all automatic and atomic. We have a background process running on laptops to download the new image when the laptops are in the school network. When the image file is changed in Puavo, the laptop gets the new image name in its configuration. If a diff is available from the boot server, it loads it and a new image is created using the diff and the old image. When the new image is ready, it is placed under images partition. There is no GRUB configuration to update as it dynamically detects the image when the system boots. In this model all updates mean rebooting, but this means that we can also rollback to previous version easily if there are any problems. Updating to new distribution version is also only a matter of image change, no lengthy upgrade process is needed.
If you know how LTSP servers work, you are probably wondering how we manage LTSP servers. They are also netbooting the same image. LTSP-pnp uses different tricks to create the fat client image from the server, but we are now creating a single image that boots also as an LTSP server. The image is built using Puppet rules so it is a repeatable process and building the 7GB image takes now some 15-20 minutes on a beefy server. At school there’s just one boot server that has a “normal” Ubuntu server installation. Everything else runs from it.
Boot servers as Puavo slaves
So now we have the netbooting teachers' workstations providing a wireless network for the laptops that use the same image as everything else. One can install it pretty much on anything and all the needed configuration is stored in Puavo. One can configure everything centrally in one place and the boot servers have a slave LDAP directory with all the configuration data. Boot servers do not need the management tools installed which makes installation and management easy.

If you want to learn more, it’s all on Github. Puavo started as an internal tool and there are no other users for it at the moment, but we’d be more than happy to help if you want to give it a try. There is also Ubuntu packaging available at archive.opinsys.fi for the brave.
Veli-Matti Lintu
]]>







 The local vendors provided us the test hardware and not all models are the newest ones available. Most manufacturers use the same technology in different models, so the test results from one model often tell a lot about the whole product line. We cannot say anything for certain about not tested models, though.
In linux usability the best were Smartboard and Promethean. Linux support was quite polished and also the physical hardware were convincing. Both have reasonably well packaged software that have more advanced features than the rest. Dymo's MimioTeach was also interesting and it shines in use cases where mobility is a requirement. Overall impression of Mimio suffers from unpolished software packaging and lack of Finnish translation. Cleverboards had quite a few problems mostly caused by unfinished linux software.
Tested features have been compiled in the following table and every whiteboard model has its own article.
The local vendors provided us the test hardware and not all models are the newest ones available. Most manufacturers use the same technology in different models, so the test results from one model often tell a lot about the whole product line. We cannot say anything for certain about not tested models, though.
In linux usability the best were Smartboard and Promethean. Linux support was quite polished and also the physical hardware were convincing. Both have reasonably well packaged software that have more advanced features than the rest. Dymo's MimioTeach was also interesting and it shines in use cases where mobility is a requirement. Overall impression of Mimio suffers from unpolished software packaging and lack of Finnish translation. Cleverboards had quite a few problems mostly caused by unfinished linux software.
Tested features have been compiled in the following table and every whiteboard model has its own article.
 Only basic features were tested. It should be noted that different whiteboard models from same manufacturer may support different features even with same software packages. It is not possible to name a single best model from the tested models as different use cases require different features. Smartboard has the best linux support at the moment and the software worked as it should. For centrally managed environments all software packages need development to enable central license management. Currently license files need to be found manually from the filesystem after debugging the software, but this is far for user friendly. LTSP systems are spreading in schools all over the world making this an issue in many places.
Firmware updates were done only when absolutely necessary - meaning that only Mimio was updated as it wouldn't work otherwise. Smartboard suggested an update, but it wasn't done. There were no big differences in resource usage between the different software packages. Adding video and flash elements caused load to go up suddenly on all of them. In normal usage there were no big problems with memory usage or performance.
Biggest noticeable difference between the different whiteboards were touch sensitivity and latency. Latency here means the delay that can be seen when drawing on the board - does the mouse follow the pen/finger immediately or does it take some time to react. Mimio had the smallest latency that had nearly immediate response even when drawing with fast movements. Sensitivity means how well the whiteboard senses touch. For example with Promethean all testers had trouble drawing solid lines because the line would have breaks with it as the whiteboard didn't sense the touch all the time.
Promethean was the only one to allow moving the mouse without pressing the left mouse key at the same time. This can be done by keeping the pen within a couple millimeters from the whiteboard. Touching the whiteboard means pressing the mouse key. All the other models always simulate pressing mouse button when touch is recognized.
The table below summarises technical features. Various problems with Cleverboard Lynx 4.0 software may have caused some things to be reported incorrectly.
Only basic features were tested. It should be noted that different whiteboard models from same manufacturer may support different features even with same software packages. It is not possible to name a single best model from the tested models as different use cases require different features. Smartboard has the best linux support at the moment and the software worked as it should. For centrally managed environments all software packages need development to enable central license management. Currently license files need to be found manually from the filesystem after debugging the software, but this is far for user friendly. LTSP systems are spreading in schools all over the world making this an issue in many places.
Firmware updates were done only when absolutely necessary - meaning that only Mimio was updated as it wouldn't work otherwise. Smartboard suggested an update, but it wasn't done. There were no big differences in resource usage between the different software packages. Adding video and flash elements caused load to go up suddenly on all of them. In normal usage there were no big problems with memory usage or performance.
Biggest noticeable difference between the different whiteboards were touch sensitivity and latency. Latency here means the delay that can be seen when drawing on the board - does the mouse follow the pen/finger immediately or does it take some time to react. Mimio had the smallest latency that had nearly immediate response even when drawing with fast movements. Sensitivity means how well the whiteboard senses touch. For example with Promethean all testers had trouble drawing solid lines because the line would have breaks with it as the whiteboard didn't sense the touch all the time.
Promethean was the only one to allow moving the mouse without pressing the left mouse key at the same time. This can be done by keeping the pen within a couple millimeters from the whiteboard. Touching the whiteboard means pressing the mouse key. All the other models always simulate pressing mouse button when touch is recognized.
The table below summarises technical features. Various problems with Cleverboard Lynx 4.0 software may have caused some things to be reported incorrectly.